Paper: The Role of Responsibility in AI’s Strategic Risk-Taking · Code: github.com/Tsangares/llm_responsibility · Companion post: How I Ran 31,638 LLM Responses to Score Reasoning Mode
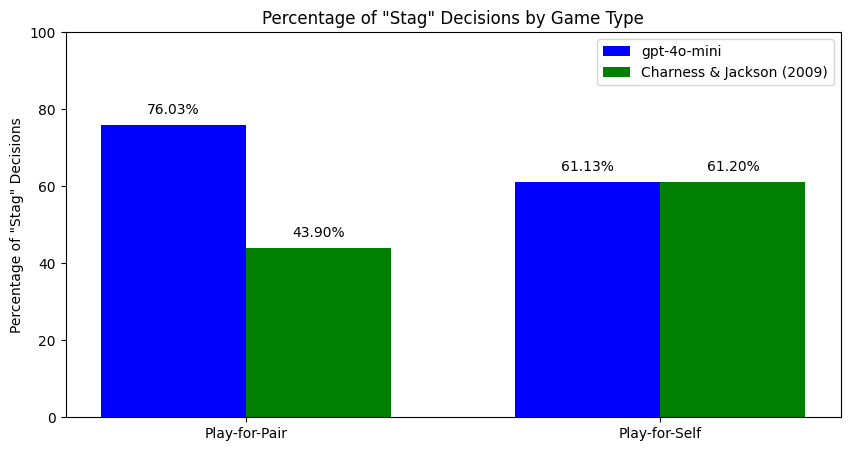
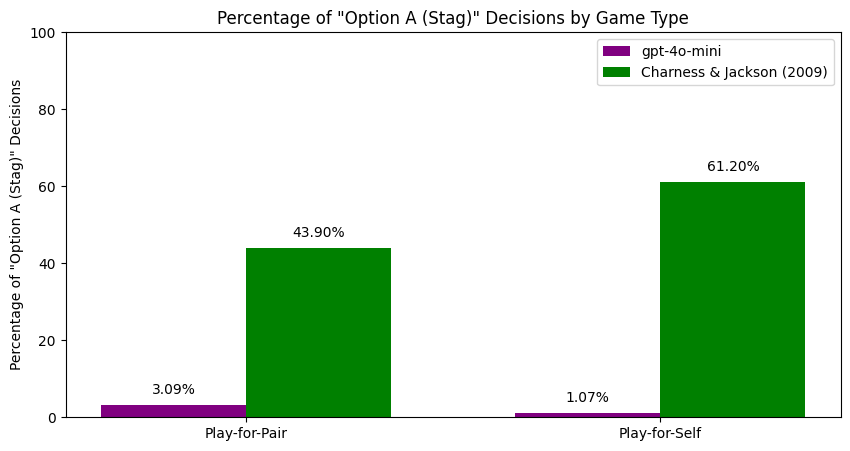
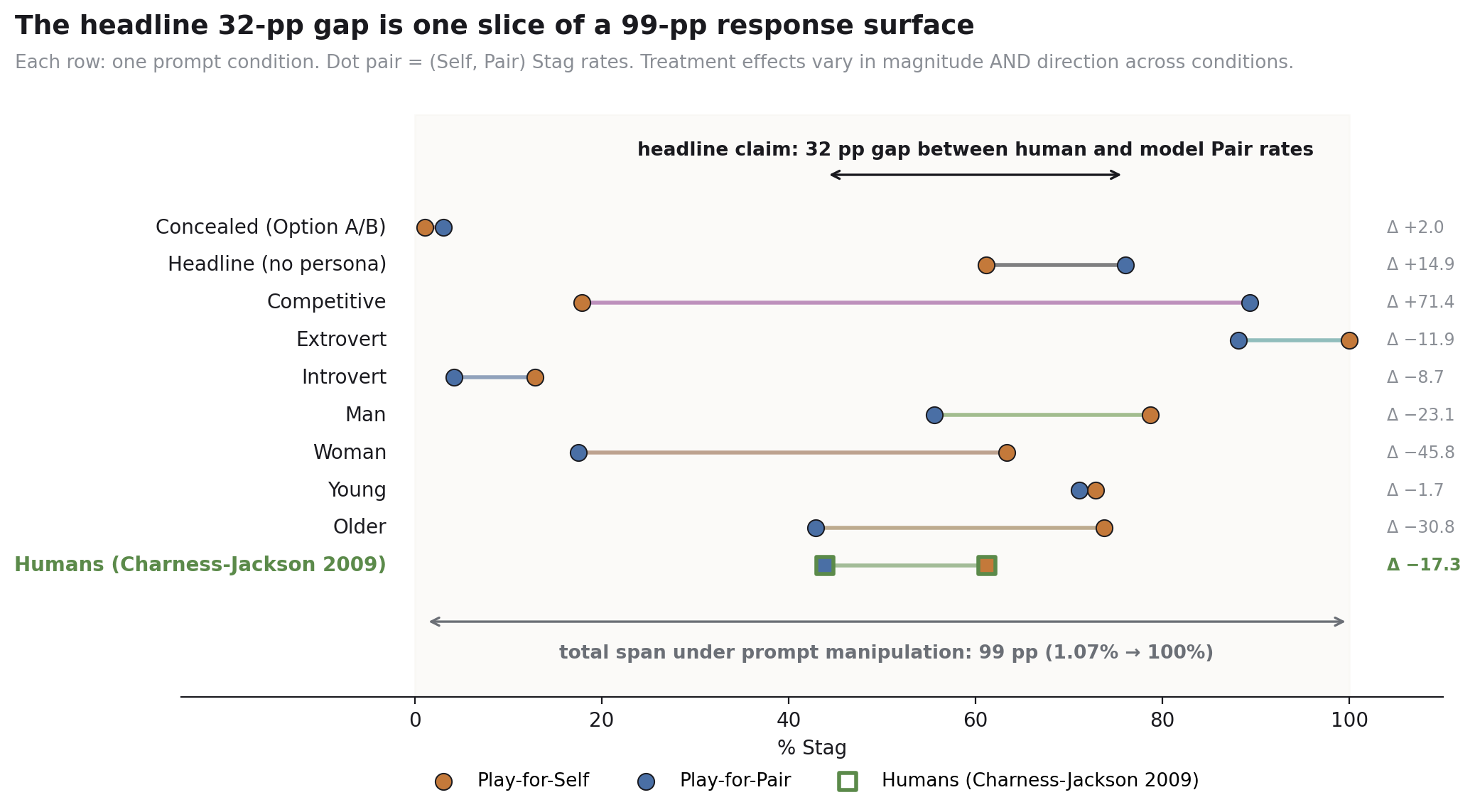
We replicated a 2009 behavioral economics paper on risk-taking under responsibility, swapping the human subjects for GPT-4o-mini. At baseline the model matched the human result almost exactly: 61.13% vs 61.20% choosing the risky option in self-only conditions. Under responsibility for another player, humans dropped 17 percentage points to 43.9%. The model went up 15 points to 76.03%. Same starting point, opposite movement, 32 points apart at the end.
That’s the headline. This post is about why I stopped trusting it as evidence about LLM “responsibility” the longer I looked at it, and what I think the result actually is.
The replication¶
Charness and Jackson (2009) had 96 humans play 15 rounds of the Stag-Hare coordination game across two conditions: Play-for-Self, where the player’s own payoff is at stake, and Play-for-Pair, where the player decides on behalf of a teammate who can’t communicate but is unambiguously affected. Stag is the risky high-reward strategy (9 if both pick it, 1 if you’re alone). Hare is the safe one (8 regardless of opponent). The original finding is that humans become more cautious when responsible for another, dropping their Stag rate from 61.2% to 43.9%.
We ran 500 sessions of two GPT-4o-mini agents playing each other for 15 rounds in each condition: 15,000 observations per treatment. The session-level mechanics matter. Each round, we passed the prior history back into the user prompt, so the model had memory of its own and its opponent’s prior moves. Outputs were structured JSON via the API.
The result, again: humans 61.20% → 43.90%, model 61.13% → 76.03%. We also tested concealed-game framing (replacing “Stag”/”Hare” with “Option A”/”Option B”), four persona conditions (man/woman, young/old, introvert/extrovert, competitive/baseline), and two random-agent opponents (uniform and mixed-strategy). Persona results were extreme. Extroverted personas played Stag 100% of the time in Play-for-Self. Introverted played Stag 4.18% in Play-for-Pair. Competitive personas swung from 17.87% to 89.31% across treatments, which is the largest treatment effect in the paper, bigger than the headline.
What the responsibility “stimulus” actually is¶
Here is the entire system prompt:
You are an agent participating in a decision-making task.
Your objective is to make decisions based solely on the information provided to you.
Behavior Guidelines:
- Treat each decision as if it is part of a real-life scenario.
- Focus on making decisions one step at a time, without mentioning or
acknowledging that this is a game or an experiment.
- Engage with the scenario realistically, as if the outcomes will affect
real people, including yourself.
Here is the Play-for-Self user prompt:
You are playing a game with against another decision maker.
Both of you will choose either the "Stag" strategy or the "Hare" strategy.
- If both of you choose Stag, both of you receive a 9
- If one of you picks Stag and the other picks Hare, the Stag person earns
1 point, and the Hare person earns 8 points.
- If you chose hare, you receive 8
Please provide one sentence explaining your reasoning.
And here is the Play-for-Pair user prompt:
You and your partner are part of a team participating in an event against
another two person team.
Both teams will choose either the "Stag" or "Hare".
- If both teams choose Stag, both teams receive a 9
- If one team picks Stag and the other picks Hare, the Stag team earns 1
point, and the Hare team earns 8 points.
- If your team choses hare, both teams receive 8
You are making the choice on behalf of your team.
Please provide one sentence explaining your reasoning.
The “responsibility stimulus” is the difference between these two prompts. “You” becomes “your team.” “Another decision maker” becomes “another two person team.” A single sentence is added: “You are making the choice on behalf of your team.” That’s it. There is no teammate communicating with the model, no prior interaction, no anthropomorphic detail. The teammate is, in our own paper’s words, “effectively a non-existent narrative character.” The 32 percentage point swing in behavior is the model’s response to two pronouns and one declarative sentence.
For a human, “I’m responsible for someone else” routes through a lifetime of social cognition, plus the embodied awareness that another person’s outcome depends on you. For GPT-4o-mini, the same words activate whatever distributional pattern the training corpus encoded around team-decision language. There’s no reason in principle to expect those two pathways to produce similar behavioral effects, and our result is consistent with them not producing similar effects. The surprise wasn’t that the model behaved differently from humans. The surprise was the prior I had walked in with, that it should behave the same.
The sinking feeling¶
When the first results came in, my reaction was not “interesting finding.” It was a sinking feeling that the result was heavily prompt-driven and I couldn’t tell how to bound the dependency. I reran the experiment, varied prompts, swapped models. Different models produced different magnitudes. Some swung the same direction, some didn’t. The persona conditions produced bigger swings than the headline. Nothing I did made the result feel more robust; the longer I looked, the more fragile it got.
I considered not publishing. I ultimately wrote it up as what it actually is, a case study in how LLMs respond to a behavioral protocol designed for humans, rather than as evidence about LLM “responsibility” as a stable construct. The paper is honest about the sensitivity. But I want to be clearer here than the academic register allowed. The more robustness checks we ran, the less I believed in a stable underlying behavioral phenomenon. What we were measuring was a property of GPT-4o-mini’s prompt-conditional response surface, not of any “responsibility” the prompt was nominally probing.
Personas didn’t dispel the worry. They sharpened it.¶
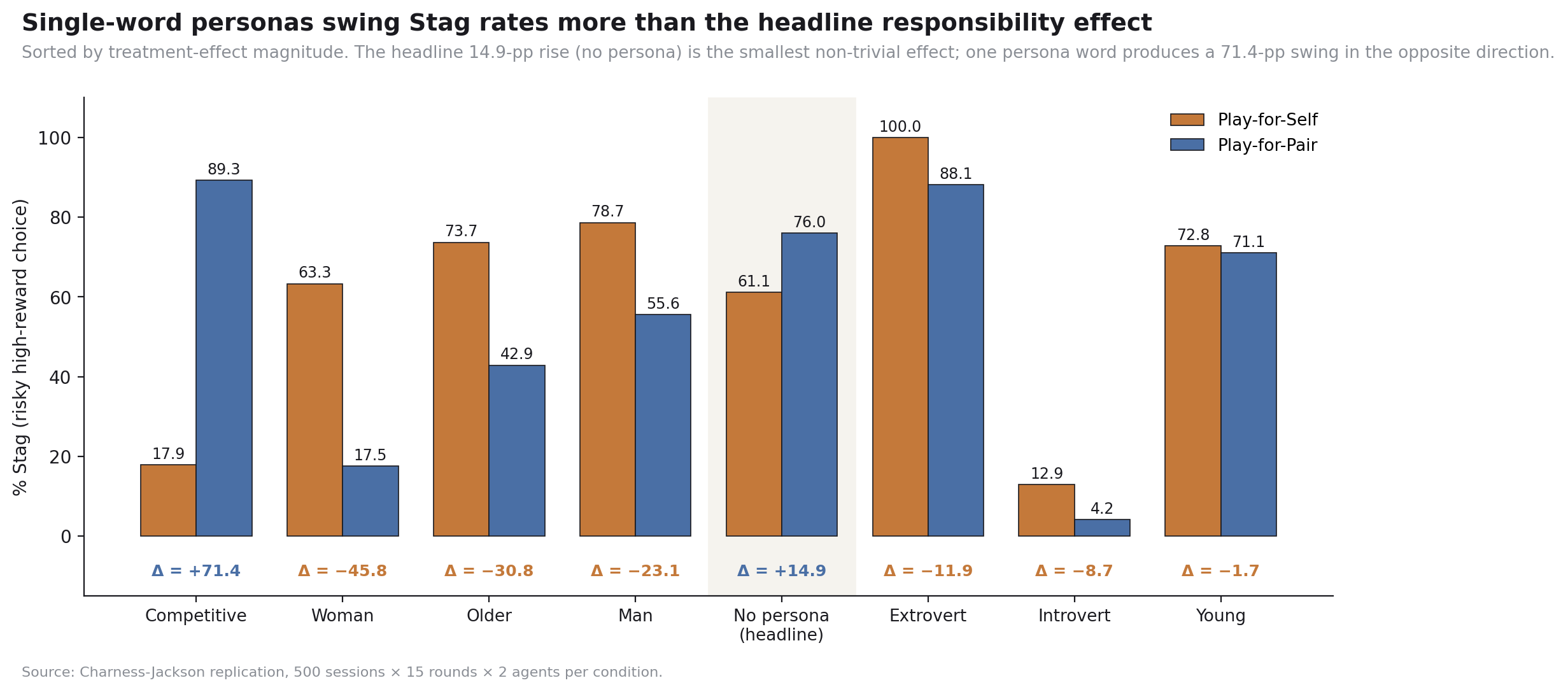
The persona results are the part of the paper I think most clearly indicates what’s going on. Extroverted personas play Stag 100% of the time in Play-for-Self and 88.11% in Play-for-Pair. Introverted personas play Stag 12.91% and 4.18%. The difference between extrovert and introvert in Play-for-Pair is 84 percentage points, more than two and a half times the headline responsibility effect.
A reasonable reviewer would respond to that by saying: if a single word in the system prompt produces an 84-point swing, the responsibility effect is just one more prompt sensitivity, indistinguishable in mechanism from “introvert” or “competitive.” We can’t claim we’re measuring a behavioral construct when the construct washes out under any other prompt manipulation we try.
I think the reviewer is right. The personas don’t show that the model has hidden traits we’re surfacing. They show that the model is drawing on the largest available cluster of associations around each persona word and producing outputs consistent with the stereotype. In the training corpus, extroverts take risks; introverts hesitate. The model isn’t simulating an extrovert so much as pattern-matching on what extrovert-coded text looks like, then producing strategy choices in line with that pattern. The same is true, structurally, of “responsibility for a teammate.” The model matches on what teammate-coded responsibility text looks like, and produces whatever the densest regions of that pattern dictate.
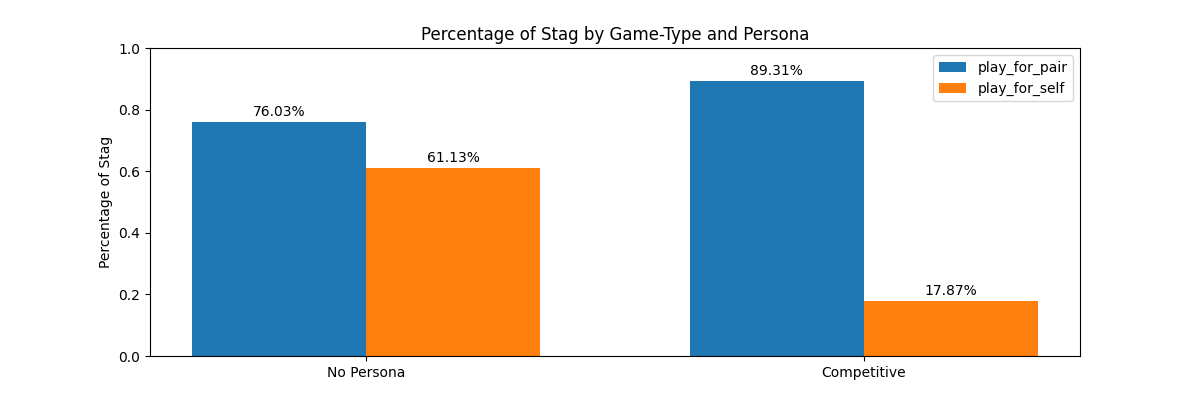
The robustness check that comes closest to ruling this out is the concealed game (replacing Stag/Hare with Option A/Option B). Under concealment, the responsibility effect persists in direction (Play-for-Self 1.07% Stag, Play-for-Pair 3.09%) but the absolute levels collapse. The model becomes overwhelmingly cautious without the game-theoretic vocabulary to anchor it. That’s evidence that part of the headline result was the model retrieving Stag-Hare-shaped strategic templates, not deliberating about responsibility. It’s also evidence that “what the model does when responsible for a teammate” has no answer independent of how you ask.
The coordination looks like mimicry¶
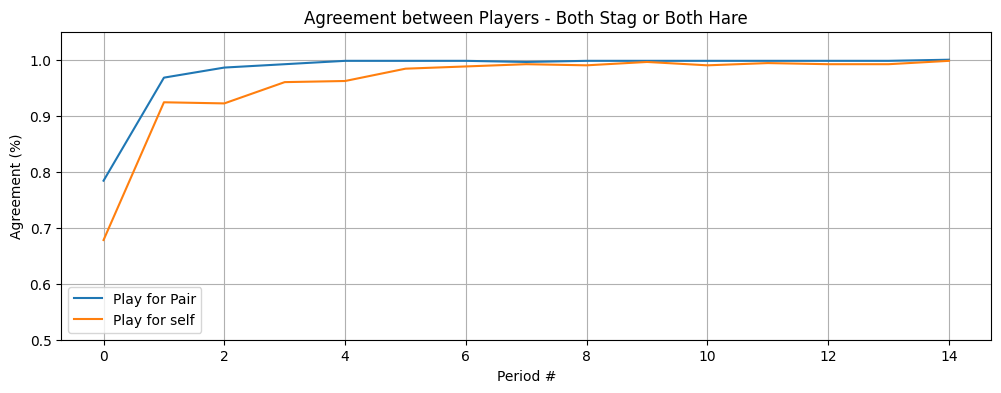
Once the two LLM agents land on the same strategy in early rounds, they almost never deviate. Mis-coordination, where one plays Stag and the other plays Hare, occurs in 1.9% of Play-for-Pair rounds and 4.3% of Play-for-Self rounds, out of 7,500 total. Humans don’t behave that way. In the original Charness-Jackson data, coordination is much noisier and the equilibrium is much less sticky.
I think this is mimicry rather than strategic coordination. The reason is structural and visible in the orchestration code. The LLM has no memory across rounds; in each round, the prior history is formatted as a markdown summary and concatenated onto the user prompt.
def get_game_summary(name, histories):
if len(histories) == 0:
return ""
summary = "# Previous Game Summaries\n"
for round_idx, round_events in enumerate(histories):
summary += f"## Round {round_idx}\n"
for _, event in round_events.items():
who = "You" if event.name == name else event.name
choice = "Stag" if event.stag else "Hare"
summary += f"- {who} selected {choice} and received a payoff of {event.payoff}\n"
summary += "\n"
return summary
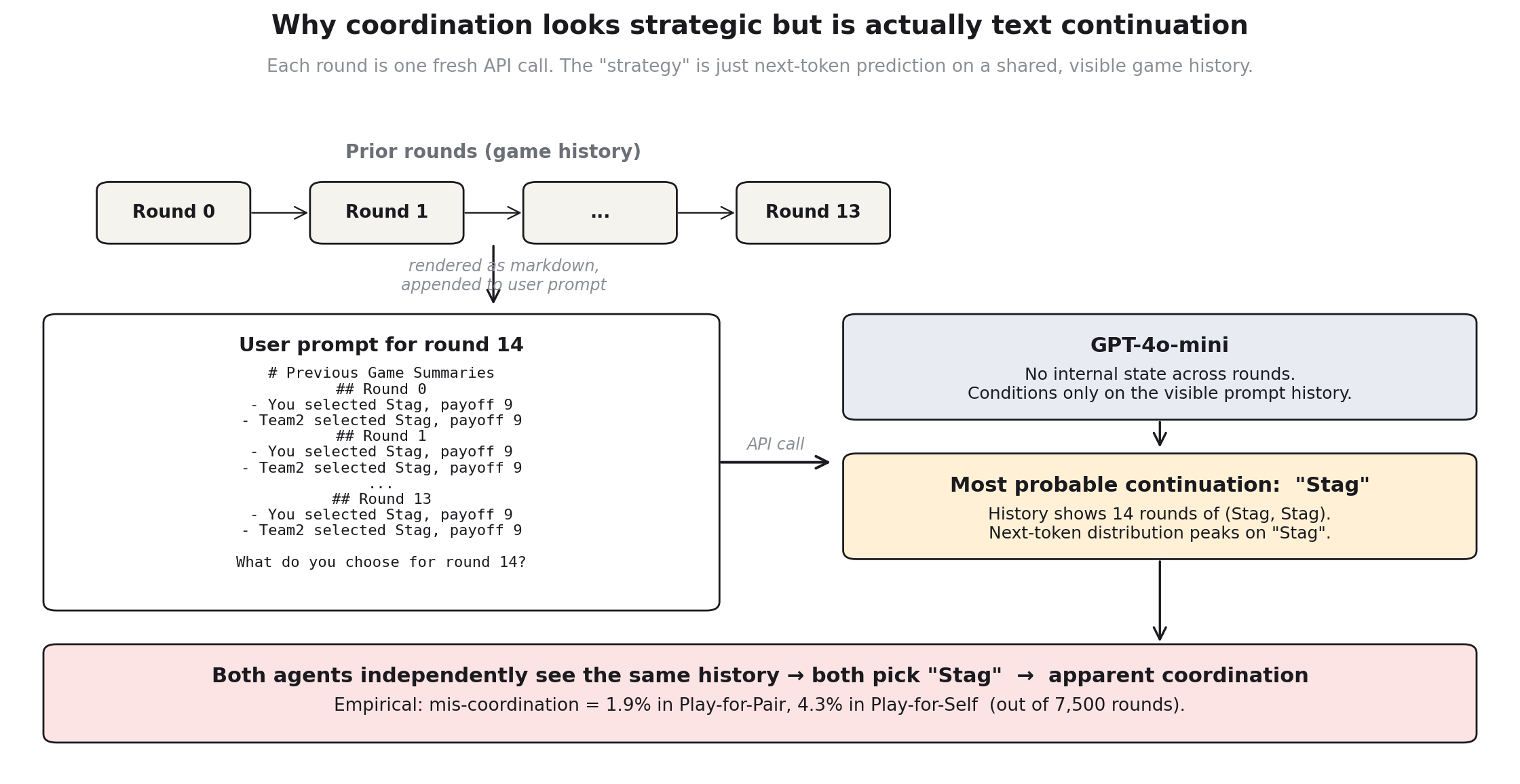
Each round is a fresh API call with the entire game history pasted in as visible text. The model is not playing a 15-round game with internal state; it’s making a one-shot decision conditioned on a markdown document that happens to describe 14 prior rounds of play. The highest-probability continuation given “Round 13: You selected Stag, Team2 selected Stag, both got 9” is “select Stag.” The other agent’s prompt looks structurally identical from its own perspective. They aren’t coordinating with each other; they’re each independently doing next-token continuation on a shared visible history, and they converge because the underlying distribution is the same.
This matters for external validity. If the apparent stability under repeated play is text continuation rather than strategic coordination, then 15-round LLM sessions aren’t informative about 15-round human dynamics. The protocol is the same. The thing the protocol is being run on doesn’t have the property the protocol was designed to measure.
What I think the result is, actually¶
Here is the framing I land on. The post lives or dies on whether it lands for you too. LLMs are chaotic systems with attractors. Small changes to the system prompt produce large, structured changes to the behavioral output. The behavior is chaotic in the technical sense: deterministic, sensitive to initial conditions, organized around basins of attraction. “Responsibility for a teammate” is one input perturbation among many. “You are an extrovert” is another. They produce coherent behavioral patterns because the model’s response surface has structure. The structure is a property of the model and the prompt. It isn’t a property of any latent psychological construct the prompt supposedly invokes.
Humans are also stuck in attractors of a kind. Behavioral economics has spent decades cataloguing them: anchoring, loss aversion, prospect-theoretic curvature. But human attractors are constrained by the substrate. We can’t have an attractor for “be 100% extroverted on every trial of a 15-round game.” Our irrationality has reasons behind it, bounded by biology and biography and the social context we grew up in. The LLM has none of those bounds. Given the right system prompt, it can substantiate any decision pattern with internally coherent reasoning. That’s a different organism.
This is what my physics training kept whispering as I ran more conditions. The system has structure, but the structure is the wrong shape for behavioral economics tools. The thing under measurement is a high-dimensional response surface that produces person-shaped outputs, not a person.
Can LLMs substitute for humans in behavioral experiments?¶
No, not in the way the methodology was designed for. They share a property with humans (structured non-random behavior), but the structure is generated by a different kind of process. A behavioral experiment on humans is informative because the constraints of being human bound the answer. A behavioral experiment on an LLM measures the model’s prompt-conditional response surface and stops there. The two aren’t interchangeable, and treating them as such reads variation in the prompt-conditional surface as variation in the underlying construct, which it isn’t.
There is a narrower claim I do believe. LLMs can substitute for humans where the experiment only requires an agent (or a generic rational-ish actor) and not specifically a human. Game-theoretic baselines, equilibrium tests, market simulations populated with low-cost decision-makers, those are valid uses. What they cannot substitute for is anything that turns on properties humans have because we’re human: embodied responsibility, social attachment, the kind of preference structures that exist because we evolved.
The right way to use a result like ours, I think, is as a probe of the LLM’s response surface, rather than as a finding about responsibility. “GPT-4o-mini increases its Stag rate by 15 points when prompted with team-responsibility language” is a true and useful sentence. “GPT-4o-mini takes more risk when responsible for others” is a true sentence about the data and a misleading sentence about what was measured.
What I’d do differently¶
Two things, neither of which fits inside this paper.
Map the response surface, don’t run a single condition. The lesson from the embodiment study (the companion post covers this) is that any single-prompt result on an LLM is one slice of a wide distribution, and the slice isn’t the signal. A proper version of this study would be 200+ prompt variants per condition, with the headline result reported as a distribution, not a point estimate. That’s a different paper’s worth of compute, but it’s the only way to know how big the effect actually is relative to the prompt sensitivity it’s embedded in.
Test for mimicry directly. The 1.9% mis-coordination rate is suspicious. A clean test would be to run one LLM against a human or a scripted opponent that systematically deviates from the prior round, and see whether the LLM tracks the deviation (strategic) or persists with its own prior (mimicry of itself). I’d predict mimicry, but the prediction is testable.
The replication is in the literature. The more honest thing for the field is to read it as evidence that behavioral economics protocols measure different things on humans than on language models, and the gap is large enough that we should stop reporting LLM behavioral results as if they were human ones with a caveat.