Paper: Participation or Observation: How Prompts Control LLM Reasoning · Repo: github.com/Tsangares/llm_embodiment · Companion post: Replicating Charness-Jackson
I built a harness to run Qwen 2.5 14B through 283 system prompts × 60 trials of the Prisoner’s Dilemma. 31,638 responses total, scored to ask whether the model deliberates as a participant or just retrieves the textbook answer. The prompts didn’t really control the decision; they controlled the reasoning mode. “Consider your values” produced 0% confession across all trials. “Make your choice now” produced 83%.
This post is about the harness, not that result. How the prompt set grew, how the inference loop is shaped, how I scored 31k free-text reasoning notes deterministically, what the storage layer looks like, and two things I almost got wrong.
How the design grew to 283 prompts¶
The 283 prompts were not the plan. The plan was to find one good system prompt and then inject personalities into it for a different paper. I started with no system prompt at all, then tried phrases like “You are human,” “This is real life,” “This is not a game.” Reading the model’s one- or two-sentence justifications, I noticed something I wasn’t looking for. With some prompts the model reasoned as if the situation were happening to it. With others it recognized a Prisoner’s Dilemma and recited the dominant strategy. Both responses landed on Confess often enough that the choice column alone hid the difference.
Once I could see that, the project pivoted. The question stopped being “which prompt should I use” and became “what makes the model treat this as a real situation versus a textbook problem, and how do you measure that from the text itself.” The 283 prompts came from combining components across five strategies (identity, reality-grounding, authenticity, moral invitation, relational framing), with formatting controls layered on top. Each component appears in many prompts and is absent from many others, which is what makes log-odds-ratio analysis at the component level identifiable.
I picked 60 trials per prompt so that each prompt-level cooperation rate has a margin of error around ±6 percentage points at 95% confidence. That’s tight enough to distinguish components whose effects are several percentage points apart, and loose enough that the extreme cases (the zero-confession prompts) read clearly without ambiguity.
The inference loop¶
The model ran locally via Ollama on a dual-GPU box (RTX 3060 + 3060 Ti). Two Ollama daemons on ports 11434 and 11435, one per card, with the runner doing round-robin dispatch across them. No API, no rate limits, no retries with exponential backoff. The bottleneck was VRAM-bound throughput, not network.
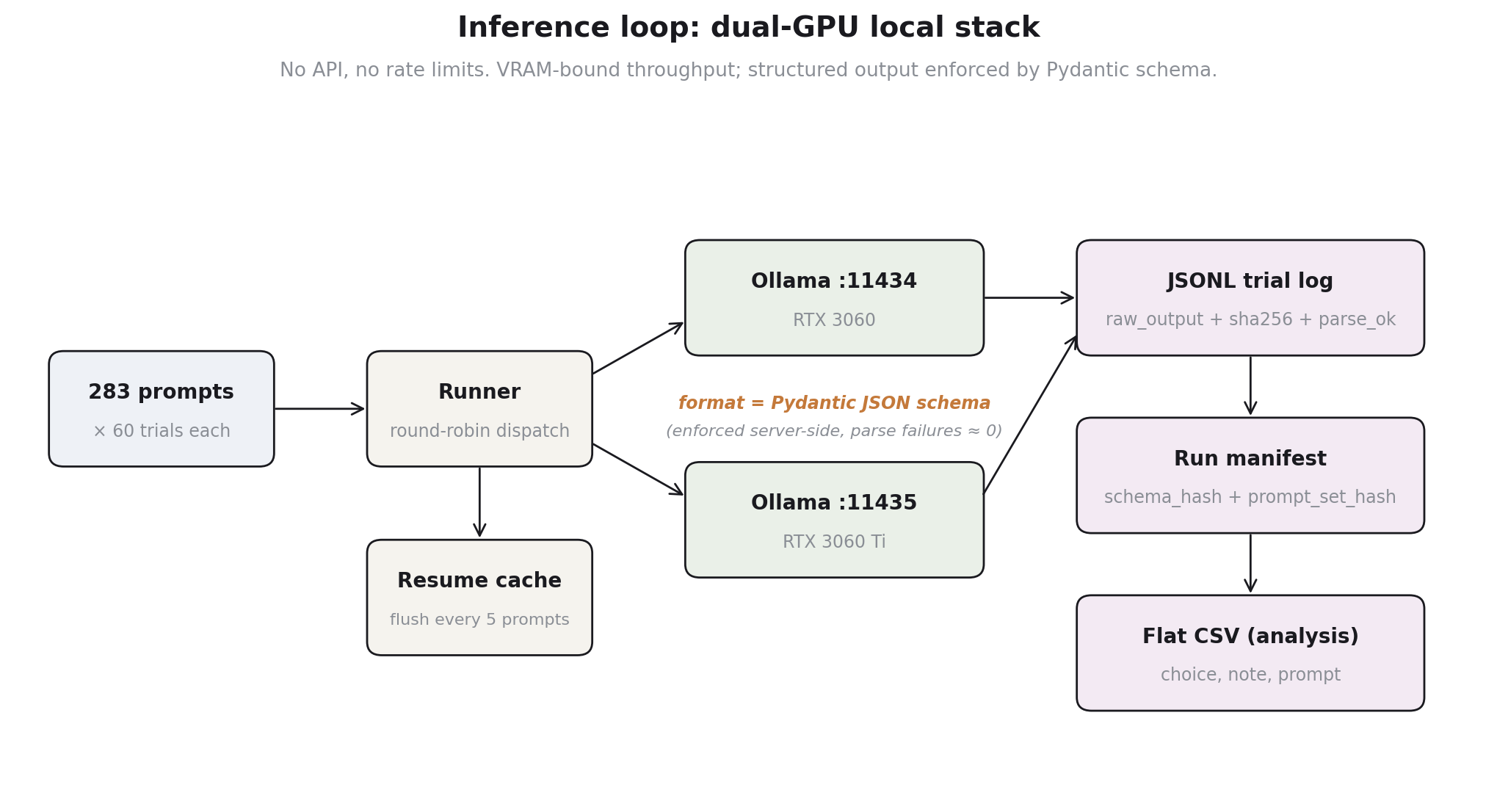
The piece worth showing is the inference call itself, because it does the load-bearing work. Ollama accepts a JSON schema in format=, and Pydantic generates that schema from a class definition. The model is constrained to emit valid JSON conforming to the schema before the response returns:
class BinaryStrategy_Prisoners(BaseModel):
choice: Literal["Stay Silent", "Confess"] = Field(...)
note: str = Field(description="A one or two sentences max description explaining your choice.")
# inside the client:
response = self.client.chat(
model=self.model,
messages=[
{"role": "system", "content": SYSTEM_PROMPT + f"\n{system_prompt}"},
{"role": "user", "content": prompt}
],
format=response_model.model_json_schema(),
options={"temperature": 0.7}
)
return response_model.model_validate_json(response.message.content)
Two consequences. Parse failures are essentially zero, because the structured-output constraint is enforced server-side rather than asked-for-politely in the prompt. And the schema becomes the contract: changing the choice enum or the note field is a typed change in one place, and the manifest stores a hash of the resolved JSON schema so that runs from different schema versions are identifiable after the fact.
Temperature is 0.7 with no fixed seed. Sampling diversity is the data, not noise: the same prompt run 60 times produces a distribution of cooperation rates, and that distribution is what the analysis consumes. A fixed seed would collapse the measurement.
Resume safety and the deficit-only refill¶
The 31,638 number is the result of multiple runs concatenated together, not one continuous job. The runner is structured so that it can be interrupted at any time and restarted without redoing work or duplicating it. The mechanism is simple: before launching, count how many valid responses already exist for each prompt in the previous output file, and only schedule the deficit:
completed_prompts = []
if old_df is not None:
prompt_counts = old_df['prompt'].astype(str).value_counts().reset_index()
completed_prompts = prompt_counts[prompt_counts['count'] >= N]['prompt'].astype(str).unique()
prompts_to_process = [p for p in base_df['Prompt']
if str(p) not in completed_prompts]
A separate cache file (cache/temp_notes_<model>.json) flushes the in-memory results list every 5 completed prompts during a run, so a crash mid-run loses at most 5 prompts × 60 trials = 300 responses, recoverable on the next launch from the cache before the canonical CSV is rewritten.
This is the part of the harness I would build the same way again. Years of running long-tailed scraping and sampling jobs taught me that a process that cannot resume is a process that wastes a weekend the first time the power blinks. The deficit-count approach also makes it cheap to bump N from 60 to 100 later: rerun the same script, it only generates the missing 40 per prompt.
The reasoning-mode classifier¶
Each trial returns a one or two sentence “note” explaining the choice. To classify 31,638 notes deterministically, I built a six-table pattern matcher across three dimensions: grammatical perspective, ontological framing, and reasoning mode. Each dimension has an “observer” pattern set and an “embodied” pattern set, and each pattern is a regex applied to the lowercased note.
self.game_theory_terms = [
r"prisoner'?s? dilemma", r"nash equilibrium", r"game theory",
r"dominant strategy", r"payoff matrix", r"optimal strategy",
r"zero-sum", r"pareto", ...
]
self.agent_terms = [
r"\bwe\b", r"\bour\b", r"\bus\b", r"both\s+of\s+us",
r"my\s+accomplice\s+and\s+(?:I|me)", r"together\b", ...
]
# and four more tables.
# Pattern matches are weighted into composite scores:
observer_score = (game_theory_lang * 3 + # strong signal
optimization_lang * 2 + # moderate
abstract_framing * 1) # weak
agent_score = (agent_language * 2 +
social_reasoning * 2 +
immediacy_framing * 1)
mode = "observer" if observer_score > agent_score else "agent"
A few things about this design that matter for reproducibility. The classifier is fully deterministic given the input text, and it runs on a 31k-row dataframe in seconds. The weights are theory-driven, not learned, so you can argue with the choice of 3-vs-2-vs-1 and rerun. The pattern set is also small enough to read end-to-end, which means failures of the classifier are auditable: if a note is misclassified, you can grep through the patterns and see why.
The price for that simplicity is context-blindness. The pattern \brisk\b would naively flag strategic vocabulary, but the phrase that actually appears in cooperative responses is “avoid the risk of betrayal.” Counting tokens, not phrases, would treat both as equally observer-coded. I avoided that by being conservative in the original keyword set, but the data-driven discovery step (described in the next section) was what surfaced the failure modes I had not anticipated.
Storage schema¶
Two layers: a per-run manifest, and a per-trial JSONL log. The manifest captures everything that’s not specific to one trial.
{
"run_id": "RUN_QWEN25_14B",
"created_utc": "2026-01-15T10:09:39+00:00",
"prefix_file_sha256": "4a96da6ec8...",
"schema": { "type": "object",
"properties": { "choice": {"type":"string","enum":["Stay Silent","Confess"]},
"note": {"type":"string"} } },
"format_schema_hash": "c27182f35d...",
"options": {"temperature": 0.7, "top_p": 0.9, "top_k": 40},
"models": ["qwen2.5:14b-multi"]
}
The two hashes do real work. The prefix_file_sha256 pins the prompt set, so I can tell whether two runs used the same 283 prompts or whether someone edited the CSV between them. The format_schema_hash pins the output schema, so a run that ever returned “Cooperate”/”Defect” rather than “Stay Silent”/”Confess” is identifiable as schema-incompatible without reading any rows.
Each trial then writes a JSONL line: run_id, ts_utc, model, prompt_id, prompt, trial_id, attempt_id, parse_ok, choice, note, raw_output, raw_output_hash, error, options, format_schema_hash. The raw_output and raw_output_hash matter for one reason: when the classifier behaves unexpectedly, I want to inspect the actual model bytes, not the parsed Pydantic dump, to rule out parsing artifacts. The hash lets me deduplicate identical generations across runs without comparing strings.
The flat CSV that the analysis notebook actually consumes is a downcast of the JSONL: just choice, note, prompt. JSONL is the durable record, CSV is the working surface.
Two things I almost got wrong¶
The pipeline ran clean. The places I had to back myself off a wrong claim were both in the analysis layer.
Cooperation almost ate embodiment. The composite embodiment score correlates r = -0.54 with confession at the response level. That sounded clean until I sat with what it could mean. If the linguistic markers I called “embodied” are just the words people use when they cooperate, then the score and the choice are two measurements of the same thing dressed differently, and the paper collapses to “prompts that ask about values cause cooperation,” which isn’t a finding.
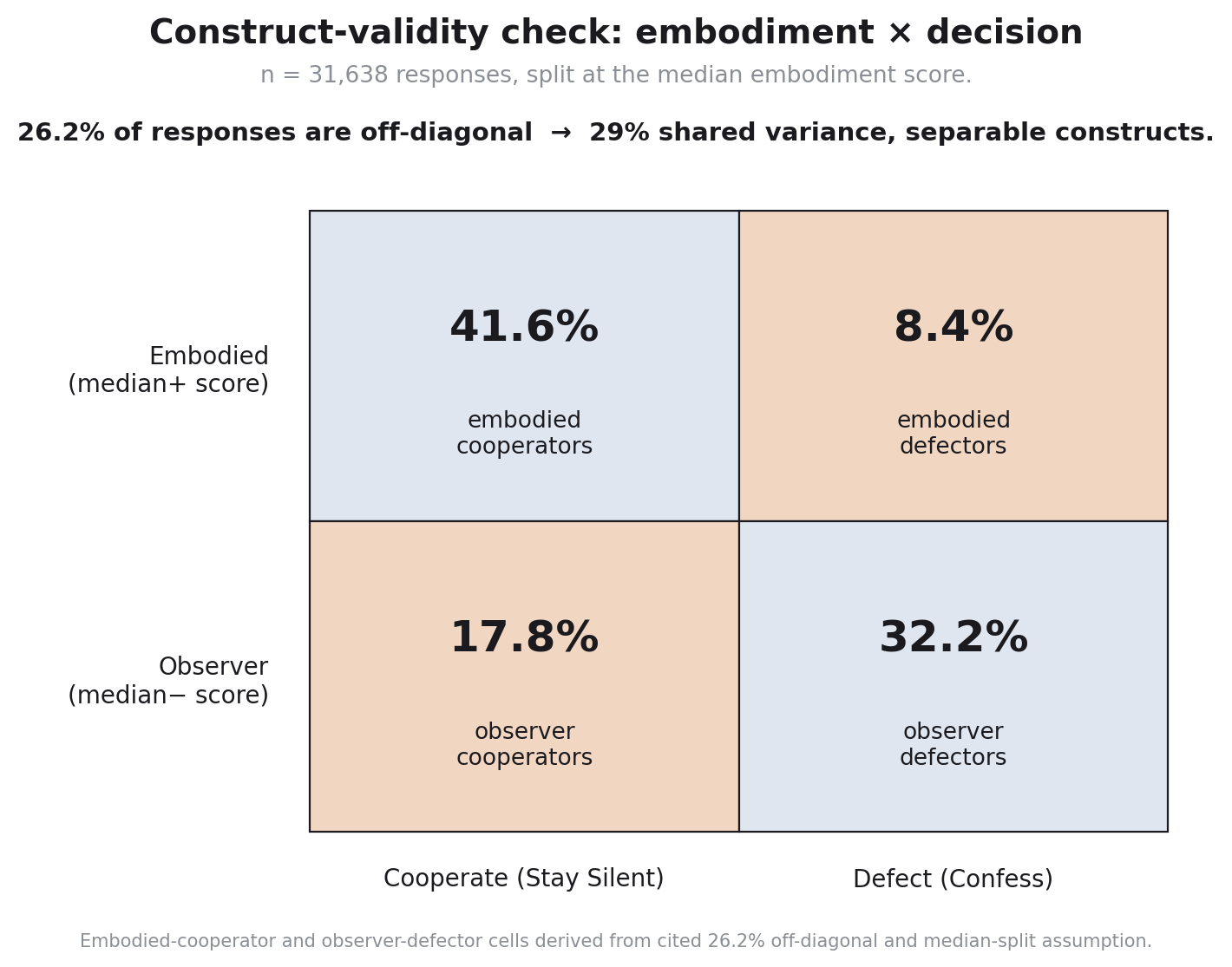
The fix was a construct-validity check: split responses at the median embodiment score and cross with decision. If embodiment is cooperation, the off-diagonal cells (high-embodiment defectors and low-embodiment cooperators) should be empty. They were not. 26.2% of the 31,638 responses fell off-diagonal: 8.4% embodied defectors, 17.8% observer cooperators. The two constructs share 29% of variance, leaving 71% unshared. That is what made the embodiment score a separable construct rather than a relabeling of the choice column. If I had not run that check, I would have published a result that was structurally circular.
The first-person assumption was wrong in the way that matters. The original framework treated grammatical perspective as a binary: first-person (embodied) versus third-person (observer). The keyword set lumped “I”, “my”, “me”, “we”, “our”, “us” together as embodied markers. When I computed log-odds ratios on the actual data, first-person plural pronouns (we/our/us) had LOR < -1.8, strongly predicting cooperation. First-person singular pronouns (I/my/me) had LOR ≈ 0 and did not discriminate at all.
This wasn’t a coding bug; the regex tables were doing exactly what I wrote them to do. It was a category bug. The model can reason in the first person and still be optimizing: “I want to minimize my sentence” is just as observer-mode as “a rational agent would minimize sentence.” The thing that separates the modes is whether the model uses “we.” A bottom-up vocabulary discovery pass on the top and bottom 10% of embodiment scores also surfaced something I hadn’t coded for at all: second-person pronouns (“you get,” “you assume,” “what your”) were among the strongest observer signals, because the model addresses an external “you” being advised on optimal play. Embodied mode says “we face this.” Observer mode says “you should do this.” That distinction was absent from my a priori marker set and is now the most discriminating piece of the refined classifier.
In both cases, the harness produced the data that exposed the methodological hole. The pipeline did not need to break for the result to be wrong; the analysis layer is where the wrong result would have lived.
What I’d build differently next time¶
Three things, in order of how badly I want them.
A game-agnostic harness. Right now the runner is hardcoded to the Prisoner’s Dilemma user prompt and the binary {Stay Silent, Confess} schema. The repo has scaffolding for five other games (Dictator, Ultimatum, Public Goods, Trust, Volunteer’s Dilemma), but the embodiment classifier and the prompt-component design were tuned to the Prisoner’s Dilemma. Generalizing this is a real research project, not just an engineering one, because the linguistic markers of “playing as a participant” almost certainly differ across games. The Dictator game has no opponent to address, so second-person observer signals will look different. Building this right would mean rerunning the LOR-on-vocabulary discovery step per game and seeing whether the across-game core of embodiment is stable.
A model-scale sweep. The whole study is on Qwen 2.5 14B because that is what fit on the dual-3060 box with no budget. The literature suggests larger models lean further into observer mode by default. With API access to a Llama 3 70B, GPT-4o, and a 1B-class model, the same harness would produce a model-size axis that the current paper cannot speak to.
A learned classifier. The pattern-table approach is auditable and fast, but it cannot pick up second-person address until I notice it should. With the 31,638-row corpus and the composite score as a soft label, a small fine-tuned classifier or a calibrated LLM-judge would likely outperform the regexes on edge cases. The reason I did not build this for the paper is the circularity risk: training a classifier on labels generated by a regex makes the classifier a smoother regex. A clean version would label a few thousand notes by hand and train against those, with the regex-based score as a baseline rather than ground truth.
The harness I have is good enough to support the result that’s in the paper. The version I want would let me ask whether the result generalizes.