Code: github.com/Tsangares/manny_mcp/tree/main/manny_driver · Companion posts: Failure-mode taxonomy, Faking phenomenon
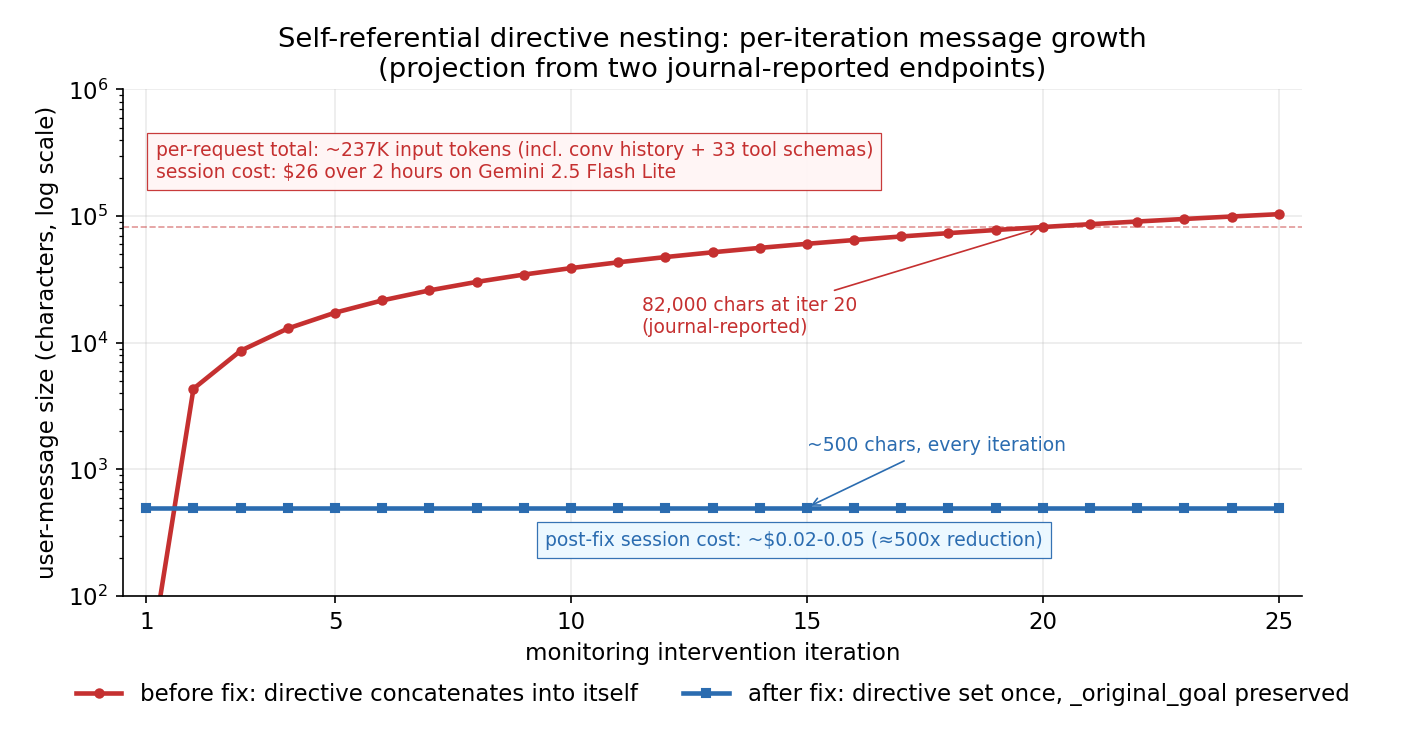
A two-hour autonomous chicken-farming session on Gemini 2.5 Flash Lite billed $26. A sampled per-request payload measured ~237,000 input tokens against ~7 output tokens. The cause was one Python field that the agent both read and overwrote in the same operation; the payload grew without bound across iterations because of it.
The arithmetic backs out cleanly only if the firing rate was much faster than the nominal 30-second monitoring interval. At Flash Lite’s $0.10/M input-token list price, $26 over 237K input tokens is about 1,100 requests in two hours, or roughly one every 6.5 seconds. The configured monitoring_interval_seconds was 30, but the recursive-nesting bug effectively chained interventions back-to-back without debouncing, so a single trigger could spawn the next while the previous was still in flight. The post is about a control-flow bug that inflates two things at once: per-request payload size and request rate. The rate inflation is the part that makes naive 30-second-interval arithmetic underestimate the bill by about 5x.
The bug¶
The driver agent has a monitoring mode that runs after the main directive completes (for example, after KILL_LOOP Chicken is dispatched, monitoring polls game state every few seconds to react to inventory-full or stuck-XP conditions). When monitoring detects an issue, it calls run_directive again with an intervention message. The intervention is supposed to embed the original goal so the LLM has context:
# manny_driver/agent.py, original
await self.run_directive(
f"Monitoring detected an issue: {trigger}. "
f"Original goal: {self._current_directive}. "
"Handle this with 1-2 commands, then STOP."
)
run_directive sets self._current_directive = directive on every call. So the next time monitoring fires, self._current_directive is no longer the original goal; it’s the entire previous intervention text including its embedded “Original goal:” prefix. After 20 iterations the field looks like this:
Iteration 1: "Original goal: Kill chickens"
Iteration 2: "Original goal: Monitoring detected... Original goal: Kill chickens... Handle with 1-2 commands"
Iteration 3: "Original goal: Monitoring detected... Original goal: Monitoring detected... Original goal: Kill chickens..."
...
Iteration 20+: 82,000 characters of recursive nesting
Combined with conversation history accumulating across interventions and 33 tool schemas being shipped on every request, an 82K-char user message turns into 237K tokens. The fix is structurally simple and is now in the file:
# manny_driver/agent.py:84-110, current
async def run_directive(self, directive: str, *, monitoring_intervention: bool = False):
self._running = True
if not monitoring_intervention:
self._current_directive = directive # only overwrite for top-level calls
self.stuck_detector.reset()
tool_schemas = (self._monitoring_tool_schemas
if monitoring_intervention else self._tool_schemas)
...
And at the monitoring entry point, the original goal is preserved exactly once:
# manny_driver/agent.py:309
self._original_goal = self._current_directive # Preserve for interventions
The intervention message no longer embeds _current_directive at all; it just describes the new trigger and trusts the system prompt to carry the goal context separately.
Why this is a class of bug¶
I think this is worth dwelling on for a paragraph because I keep seeing variations of it. The bug pattern is: a function reads a field at the top, derives output from it, and writes a different value into the same field at the bottom. If anything else reads that field between calls and treats it as state-of-record (here, the next monitoring trigger does exactly this), you have a feedback loop. If the value being written is structurally larger than what was read (here, the intervention text contains the original directive plus prefix and suffix), the loop is exponential.
The pattern hides behind seemingly safe local code. run_directive looks fine in isolation. The monitoring loop looks fine in isolation. The bug is in the field semantics: _current_directive was simultaneously “the directive currently executing” (read) and “the most recent thing dispatched to run_directive” (write), and those two intentions diverge the moment you start nesting calls. The fix is the _original_goal field, which gives the read-side a stable referent that the write-side never touches.
In retrospect, the right rule is that any field involved in prompt construction must have either a single writer (set once at the top of an operation), or an explicit non-overwriting code path for nested invocations. The driver now has both, via the monitoring_intervention=True keyword argument.
The secondary fixes that mattered¶
Stopping the recursive nesting fixes the per-message size, but the rest of the cost surface is untouched. Four other changes shipped in the same patch and together they account for most of the ~500x reduction the journal records ($26 down to roughly $0.02 to $0.05 for an equivalent session).
First, deterministic responses for triggers whose action is hardcoded. The system prompt told the LLM what to do when inventory was full (“Use BURY_ALL to clear bones”). Spending an LLM call to read that prompt and emit send_command("BURY_ALL") is paying for retrieval of information you already have. The fix is the trigger-handler returns a tuple instead of a string, and the monitoring loop dispatches the commands directly:
# manny_driver/agent.py:409
return ("inventory_full",
["BURY_ALL", "DROP_ALL Egg", "DROP_ALL Feather", "DROP_ALL Raw chicken"])
The journal estimates this eliminated ~95% of LLM calls during monitoring. The lesson is the obvious one once stated: if your system prompt deterministically maps a trigger to an action, the LLM is doing zero useful work in the loop and can be removed from it.
Second, clearing conversation history between independent interventions. Each monitoring fix is atomic; nothing in the previous intervention’s tool results is relevant to the next one. The fix is one line, self.conversation.clear(), called before each intervention. This stops a different growth axis from the recursive-nesting one: before the fix, intervention 10 inherited 40+ messages from interventions 1 through 9.
Third, monitoring-specific tool subset. Monitoring needs 6 tools (send_command, send_and_await, get_game_state, get_logs, query_nearby, get_command_response). The full agent ships 33. The fix builds a _monitoring_tool_schemas list at init time and passes it during interventions, saving roughly 1K tokens per call.
Fourth, Gemini’s system_instruction parameter. The 2K-token system prompt was being prepended to the first user message rather than passed to the API as a system instruction. Gemini caches system_instruction across requests; user-message content is not cached. Switching the call to pass it correctly turned a per-request 2K-token charge into a one-time cost.
Why I didn’t notice for two hours¶
The lesson worth taking from this incident is about visibility, not the fix itself. The cost stayed invisible to me the whole time, because both the Gemini and Ollama clients in the original llm_client.py returned input_tokens=0 and output_tokens=0 in every response. Provider-side usage metadata is exposed (response.usage_metadata.prompt_token_count for Gemini, data["prompt_eval_count"] for Ollama) but the client never read it. Without per-request token counts, the cost-per-session estimate was always 0 in the agent’s status output. The first signal was the $26 invoice.
The fix is two lines per provider:
# manny_driver/llm_client.py:240
llm_resp.input_tokens = getattr(response.usage_metadata, 'prompt_token_count', 0) or 0
llm_resp.output_tokens = getattr(response.usage_metadata, 'candidates_token_count', 0) or 0
# manny_driver/llm_client.py:453 (Ollama)
input_tokens=data.get("prompt_eval_count", 0) or 0,
output_tokens=data.get("eval_count", 0) or 0,
With token tracking in place, the driver now enforces a soft budget cap (max_session_cost_usd: 1.00 in config.py) that stops the run with a status message if the running cost crosses the threshold. The cap is a backstop, not a fix. It bounds how long a bug runs before I notice.
Why this generalizes¶
For an agentic eval harness, this bug is the worst kind to ship: the agent kept producing reasonable-looking outputs the whole time it was burning money. The KILL_LOOP ran. The monitoring fired. The interventions handled inventory-full correctly. From the outside, the system was working. The failure was structural and invisible because the structure being failed was the request payload, which the operator never sees in the normal monitoring view.
Two takeaways for anyone building autonomous agents on metered providers. First, instrument provider-side token metadata before you ship; the cost of a missed instrumentation call is bounded by your provider’s billing window, which is much longer than your debugging window. Second, treat any field that participates in prompt construction as if it could blow up exponentially, because if it has the read-and-overwrite shape, eventually it will. The $26 number is small; the same bug on a six-hour overnight run with a more expensive model would have been $400.