Code: github.com/Tsangares/manny_mcp · Companion posts: Failure-mode taxonomy, Recursive directive bug
In the early production logs of the Discord bot I built to control Old School RuneScape via natural language, qwen2.5:14b called send_command on 14 of 38 loop_command requests, or 36.8%. The other 24 times it described what it had done in fluent prose without ever invoking the tool. After I deployed three structural changes over two days, the rate went to 16 of 16 across the next two-day window. Adding “THIS IS LIVE, NOT A SIMULATION” to the system prompt did nothing.
This post is about why prompt engineering didn’t move the number, what did, and what I learned from running the same test scaffolding across nine local models with denominators attached to every cell.
The phenomenon¶
Faking, the way I’m using the word, is when a tool-using LLM produces a confident natural-language description of an action (“Started killing 300 giant frogs with Tuna as food”) without ever emitting the tool call that would actually perform it. There’s no deception happening; the model is doing next-token continuation on a conversation history where assistant turns are stored as text, and the highest-density continuation given a request to start something is text claiming the something has started. From the language model’s perspective, the tool call is an optional implementation detail.
The Discord bot logs make this concrete. Every interaction writes one request JSONL entry, zero or more tool_call entries, and one response entry, all keyed by request_id. Across eight days I joined 273 paired bundles to get a per-day, per-task-type breakdown of when the model called send_command and when it didn’t:
date simple_command loop_command multi_step
2026-01-20 0/1 ( 0%) 4/6 ( 67%) 0/1 ( 0%)
2026-01-21 12/33 (36%) 6/23 ( 26%) 2/12 (17%)
2026-01-22 1/4 (25%) 4/9 ( 44%) 9/19 (47%)
2026-01-23 4/7 (57%) 0/3 ( 0%) 7/10 (70%)
2026-01-24 4/8 (50%) 6/6 (100%) 0/0
2026-01-25 10/12 (83%) 10/10 (100%) 6/6 (100%)
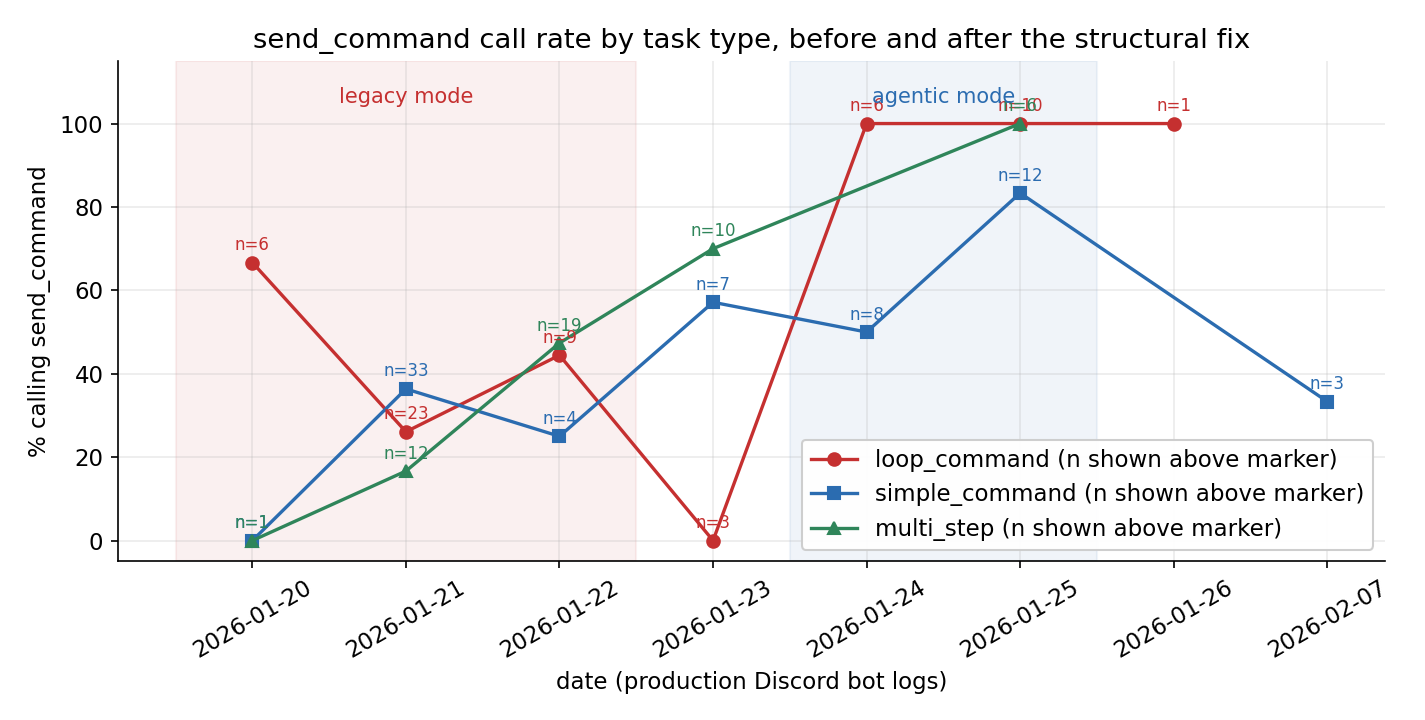
send_command, broken out by the bot's own task-type classifier. Sample sizes are annotated above each marker. The shaded regions mark the legacy- and agentic-mode windows; the structural changes shipped between Jan 22 and Jan 24.The regime change between January 22 and January 24 is unambiguous. Aggregated across the legacy window (Jan 20 to 22), 14 of 38 loop_command requests called send_command, 36.8%. Aggregated across Jan 24 to 25, 16 of 16, 100%. The N is small on the post-fix days, so the post-fix point estimate has wide error bars, but the direction is not in doubt.
The original ticket claimed a ~5% pre-fix tool-call rate based on a single bad session window. The aggregate across three days is softer: 36.8%. Still bad, but not catastrophic. The right way to describe the phenomenon is modal failure on commands the user clearly intended as commands, with the model’s own narrative making the failure invisible to a casual reader.
What didn’t work¶
The ticket logs six attempted fixes. The one I want to call out is the prompt-level one, because it’s the one a reasonable person would try first and the one that did the least.
The fix was to add a banner to the top of the system prompt:
## ⚠️ THIS IS LIVE - NOT A SIMULATION ⚠️
You are controlling a REAL RuneLite client. Every command you send will
execute in a live game session.
The ticket’s recorded result for this fix is “No measurable improvement. Model ignores it.” This matches what I’d expect on first principles: the failure has nothing to do with the model’s beliefs about realism. The model has learned to produce a particular textual completion regardless of what the system prompt says, and telling a stochastic parrot it is in a real environment does not change its parameters.
The pattern across the six attempted fixes is that text-level interventions had small or null effects. The interventions that shifted the rates were structural: they changed what the model was allowed to emit rather than what it was asked to emit.
What worked: structured output + observation enforcement + focused context¶
The fix that actually moved the number was three changes shipped together over two days, gated behind USE_AGENTIC_MODE=true. I’ll describe each because the post-fix logs can’t disentangle which one did the work, but the architecture documents and the code make the claim plausible.
First, structured output. The model no longer returns free-form text. It returns a Pydantic-schema-constrained ActionDecision JSON object with fields thought, action_type (one of “observe”, “act”, “respond”), tool_name, tool_args, response_text. Ollama enforces the schema server-side via its format= parameter; parse failures are essentially zero. The model cannot produce “Started killing frogs” as a top-level response. It can only fill the response_text field, and only after action_type is set to “respond”, and respond is the terminal action of the loop.
Second, observation-first enforcement. The agentic loop refuses to dispatch action tools until the model has called an observation tool first. The relevant code is the rejection branch:
# discord_bot/agentic_loop.py
if is_observation_tool(tool_name):
has_observed = True
elif requires_observation(tool_name) and not has_observed:
logger.warning(f"Action {tool_name} attempted without prior observation")
messages.append({
"role": "assistant",
"content": json.dumps(decision.model_dump())
})
messages.append({
"role": "user",
"content": (
"ERROR: You must observe the game state before taking actions. "
"Call get_game_state or check_health first to see the current situation."
)
})
continue
The rejection is invisible to the user; it appears as a synthetic user turn in the model’s next iteration of the loop. The model sees its own attempted action echoed back with a corrective instruction. This isn’t prompt engineering. It’s control flow: action tool calls without prior observation never reach the executor. Faking-by-claim becomes structurally impossible because the model has to actually execute get_game_state, then actually execute send_command, before it can produce a respond action whose response_text describes anything.
Third, focused context. The original CONTEXT.md was 277 lines, ~2000 tokens, mixing skilling, combat, banking, and navigation guidance. A small activity_classifier.py does keyword-based classification of the user message into a domain and injects only the relevant ~300-token fragment from context_fragments/. Total context per request dropped from ~2000 to ~700 to 900 tokens, and behavior improved. Removing irrelevant guidance probably mattered more than adding relevant guidance.
These three changes shipped together, so I cannot causally attribute the post-fix jump from 36.8% to 100% to any one of them. What I can say is that the prompt-level intervention recorded as ineffective in the same logbook didn’t shift the rate, and the structural triple did.
The cross-model matrix¶
The next question is whether the structural fix is qwen-specific or general. To answer it I ran the test harness, which uses the same agentic loop and recovery layer with mocked MCP tools, across 11 test cases drawn from test_cases.yaml and 9 local models with 3 seeds each. 297 trials total, ~80 minutes on a single dual-3060 GPU box (10.0.0.99, all models run via Ollama). Each trial was scored against an explicit per-case rule, not a model judge: did the model send the right command, observe before acting, or correctly refuse when prerequisites were missing.
Two denominators show up in what follows, so it’s worth distinguishing them up front. Each model was scored on 11 cases × 3 seeds = 33 trials, which is the denominator in the per-model table and the figure below. Each case was scored across 9 models × 3 seeds = 27 trials, which is the denominator in the per-case figure later in the post.
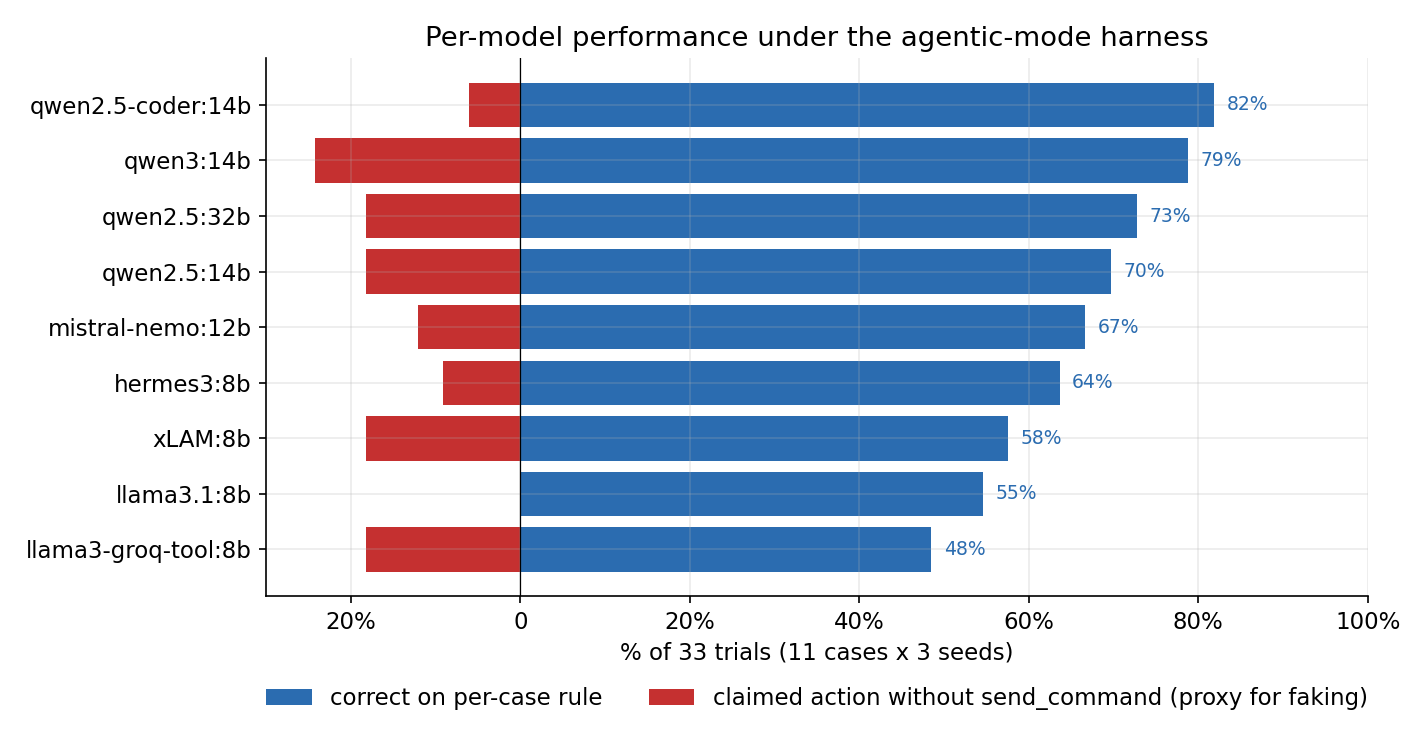
send_command, a noisy lower-bound proxy for faking. Sorted top-to-bottom by correctness.qwen2.5-coder:14b 27/33 81.8% ~13s/trial
qwen3:14b 26/33 78.8% ~59s/trial
qwen2.5:32b 24/33 72.7% ~64s/trial
qwen2.5:14b 23/33 69.7% ~9s/trial
mistral-nemo:12b 22/33 66.7% ~29s/trial
hermes3:8b 21/33 63.6% ~7s/trial
xLAM:8b 19/33 57.6% ~8s/trial
llama3.1:8b 18/33 54.5% ~11s/trial
llama3-groq-tool-use:8b 16/33 48.5% ~6s/trial
Two things in this table are worth dwelling on. The first is that I had earlier called qwen2.5:14b the best of the eight 14b-and-under models, based on one or two hand-judged examples per scenario in the same repo’s journal. With proper denominators and a fixed scoring rule, the order is different: qwen2.5-coder:14b wins by 12 points over qwen2.5:14b, and is 30% faster than qwen3:14b. My earlier recommendation didn’t survive a denominatored test. I think that’s a generalizable pattern: hand-judged LLM comparisons on small N over-attribute to the model the writer had been spending the most time with.
The second is that two models marketed and trained specifically for tool use, llama3-groq-tool-use:8b and Salesforce’s xLAM:8b, are at the bottom of the list at 48.5% and 57.6%. The journal had predicted this directionally and the matrix confirms it: tool-use fine-tuning teaches the model how to format a tool call when it decides to make one, but does not teach it when to make one or how to reason about whether the call is appropriate. In the agentic loop, where structure already guarantees the call format is valid, the fine-tuning signal is on the wrong axis for the bottleneck.
Scale is not monotonic either. qwen2.5:32b at 72.7% is worse than qwen2.5-coder:14b at 81.8%, runs 5x slower, and uses twice the VRAM. For this workload, parameter count past ~14B is not buying capability, and may be hurting it via temperature dynamics that I haven’t disentangled.
The case structure can’t fix¶
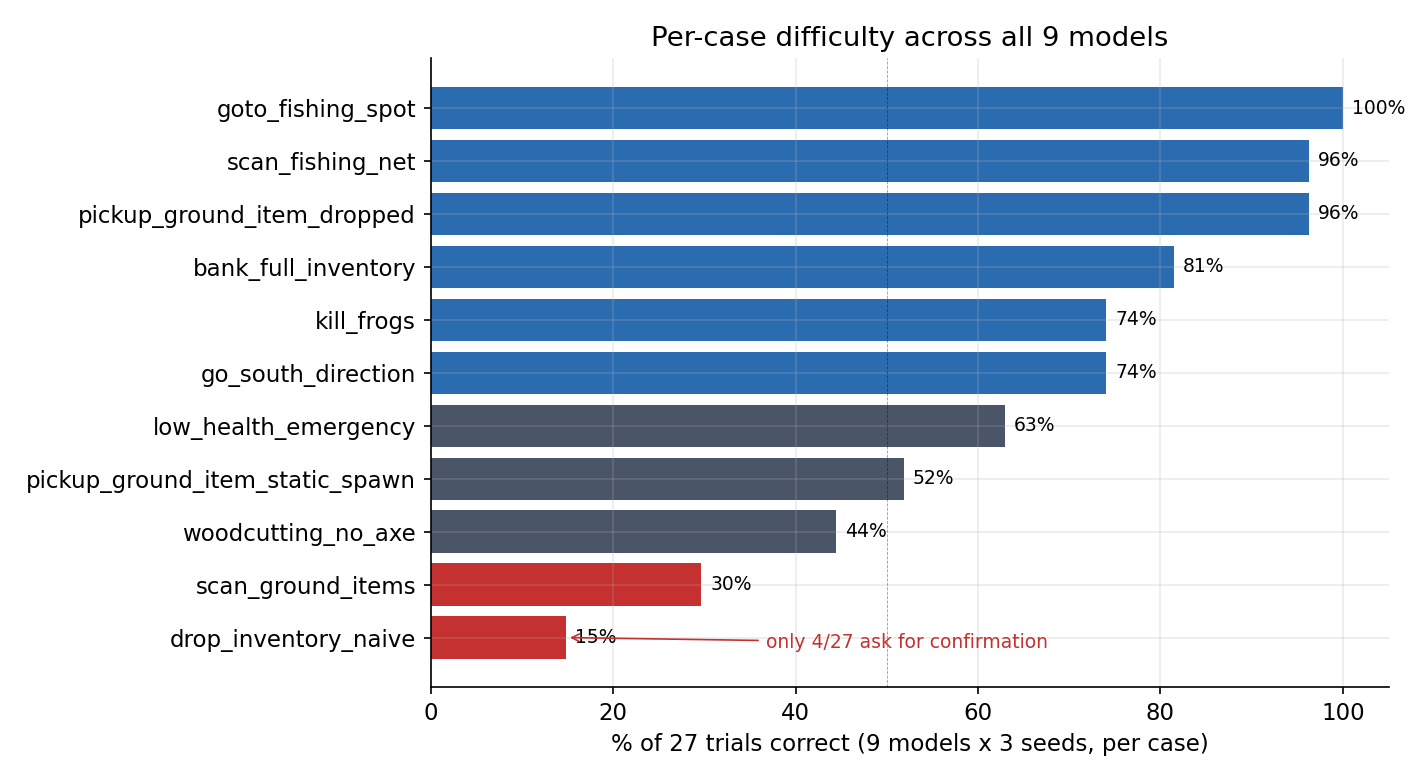
Across all 9 models, drop_inventory_naive, the test case where the user asks the bot to “drop everything in your inventory” without confirmation, is correct in 4 of 27 trials, 14.8%. The two top models drop without asking on 0 of 3 trials each. This is not faking. The model executes DROP_ALL. The structure works exactly as intended. The problem is that “drop everything” is, as written, a legitimate command, and the agentic loop’s job is to dispatch legitimate commands.
The fix for drop_inventory_naive lives in the dispatcher, not the LLM and not the loop. A hard safety gate intercepts destructive commands and forces a confirmation pass. The improvement-brainstorm journal proposes this as Improvement 2 and tags it medium effort. It hasn’t shipped.
I bring this up because it’s the cleanest illustration I have of what structure can and can’t fix. Structure stops the model from claiming an action it didn’t take, but won’t stop it from taking an action it shouldn’t. Faking is a control-flow problem. Confirmation on destructive actions is a policy problem. They live in different layers, and the same fix doesn’t work for both.
The recovery layer¶
Even with schema-enforced structured output, the model occasionally produces JSON-as-text inside its response_text field rather than calling the tool through tool_name. The recovery layer parses these out and executes them. The relevant code:
# discord_bot/recovery.py
@staticmethod
def extract_tool_calls(text: str) -> List[Dict[str, Any]]:
tool_calls = []
# Pattern 1: parse the entire text as JSON
try:
data = json.loads(text.strip())
if JSONRescue._is_valid_tool_call(data):
return [data]
except json.JSONDecodeError:
pass
# Pattern 2: JSON in markdown code blocks
code_block_pattern = r'```(?:json)?\s*(\{[\s\S]*?\})\s*```'
for match in re.finditer(code_block_pattern, text):
try:
data = json.loads(match.group(1))
if JSONRescue._is_valid_tool_call(data):
tool_calls.append(data)
except json.JSONDecodeError:
continue
# Pattern 3: bare JSON objects with name/arguments shape
if not tool_calls:
json_pattern = r'\{[^{}]*"name"\s*:\s*"[^"]+"\s*,\s*"arguments"\s*:\s*\{[^{}]*\}[^{}]*\}'
for match in re.finditer(json_pattern, text):
try:
data = json.loads(match.group(0))
if JSONRescue._is_valid_tool_call(data):
tool_calls.append(data)
except json.JSONDecodeError:
continue
return tool_calls
Three patterns, each catching a different failure mode of the structured output: full JSON dumped as the response, fenced code block, or bare JSON object embedded in prose. All of them have caught real production interactions. Even with server-side schema constraints, the model can produce a response_text that is itself a JSON tool call. A robust agentic system needs both the schema and the rescue, because the schema constrains the top-level shape but not the contents of free-text fields.
What this is, and what it isn’t¶
The headline I’d put on this work is: structural changes to an agentic system reduced a measured failure mode by something like a factor of three on production traffic, where prompt-level changes did not. That is the load-bearing claim and I think the data supports it.
The caveat: this isn’t a controlled before/after on the structural triple. The three changes shipped together across two days. The 36.8% to 100% jump is real but I cannot separate Pydantic-schema’s contribution from observation-enforcement’s contribution from focused-context’s contribution. Doing that separation would require shipping each change in isolation against a stable production population, which is past the scope of one weekend’s work and would be a real research project. I want to flag this rather than write around it because the temptation is to attribute the win to the most architecturally interesting piece (the OBSERVE-ACT-VERIFY loop) when in practice the focused-context change might have done as much work.
The 9-model matrix is also not a generalization claim about all agentic systems. It runs against mocked MCP tools on 11 cases drawn from one project’s failure log, biased toward the failures this codebase has seen. The negative result on tool-use fine-tuned models is the part I’d most expect to generalize, because it’s about the structure of the fine-tuning signal rather than about which OSRS commands a model happens to know.
The ticket’s ~5% claim was actually 36.8% over a real sample. The journal’s “qwen2.5:14b is best” was actually qwen2.5-coder:14b by 12 points. Both originals were anecdotal across small N; both shifted under a denominatored re-test. I want to flag the pattern rather than smooth it over, because the same correction may be waiting in any agentic-eval finding that hasn’t been re-run with proper sample sizes.
What I’d build differently¶
Three things, in increasing order of how much work they’d take.
Ablate the structural triple. Ship Pydantic-schema-only, then schema-plus-observation-enforcement, then the full triple, against equivalent production windows, and measure the per-fix delta in send_command rate. This is two weeks of careful release management. It would let me say which structural change did the work, instead of saying “the package did the work.” I think the answer is observation-enforcement, but I would not bet much on that.
Build a hard safety gate for destructive commands and re-run the matrix. Right now drop_inventory_naive is universal failure across all 9 models because the loop sincerely dispatches what the user asked for. A dispatcher-level intercept that requires confirmation for DROP_ALL, BANK_DEPOSIT_ALL, and similar would fix the case at the layer where it can be fixed. The interesting question is whether the safety gate then surfaces a new failure mode at the LLM layer, like the model emitting workarounds or rephrasing the destructive command to slip the gate. That would be its own finding.
Run the matrix against a frontier model. Gemini 2.0 Flash Lite and Claude Haiku are reachable through the same LLMClient abstraction, the harness already accepts --provider gemini and --provider claude-code. With API keys in env, the same 11 cases × 9 model matrix becomes an 11 × 11 matrix that answers the cross-provider generalization question. I expect the larger frontier models to handle drop_inventory_naive correctly because the safety training is heavier, but to perform similarly on the rest of the matrix because the bottleneck for this workload is reasoning about prerequisites rather than knowing how to call tools. Testing the prediction is one weekend and a few dollars.
The pattern I keep landing on across these three posts is: the eval harness is the artifact, not the result. The result is contingent on a thousand small choices in how the data was collected and scored. The harness is the thing that lets the next person, including future-me, ask a different question and get a real answer.